
















<第3回「音×機械学習」勉強会>レポート
スマホで録音した演奏のノイズは、機械学習でどこまで取り除けるか?最新技術を解説
「音×機械学習」をテーマとしたエンジニア勉強会も6月28日に無事最終回となる第3回を開催しました。朝には台風の予報もあり、天候に不安があるなかでしたが、たくさんの方に参加いただきました。

産業面での活用を紹介した第1回、音楽における機械学習について解説した第2回に続き、第3回ではさらに一歩踏み込み、機械学習によるデノイジング(ノイズ除去)とデクリッピング(音割れの復元)を取り上げて解説。このテーマはまさにEYSのInspiartプロジェクトで開発している領域です。ノイズキャンセリングというと、Web会議用のマイクやスピーカーなどに搭載されているのをよく見かけますが、実は「音楽のノイズキャンセリング」はあまり研究されてこなかったのだそう。その理由は、これまで音楽は音響設備の整ったスタジオで録音することでノイズが入らないようにするのが当たり前だったから。ですが、いまやスマートフォンでも簡単に演奏を録音できる時代です。当然、エアコンなどのノイズが入ってしまい、これらをどうやって除去するかが課題になっているのです。デクリッピングはいわゆる音割れ(クリッピング)してしまったものを機械学習で復元しようという取り組み。マイクの性能や、ミキシング処理で音割れしてしまったら、諦めるしかないと思っていましたが、機械学習でどこまで復元できるのでしょうか?
今回もInspiartチームを率いる金さんが講師に立ち、実際に自分たちが開発したものも含め、かなり多くのデモを交えての解説となりました。
楽器の響きを残して、ノイズだけが消えた!最新技術デモに驚く
そもそも「ノイズが入っている」とはどういう状態を指すのでしょうか?ざっくりとではありますが、「きれいな音に対して、余計な周波数帯が入っていること」と定義できます。このノイズ(余計な周波数帯)は音の波形を拡大すると明確に見えますし、パワースペクトログラムへ変換した際にもノイズのあり・なしで見え方が大きく異なります。

ノイズの発生要因としては、大きく「室内の環境音」と「マイクの電子回路によって生成されてしまう音」の2種類に分けられ、現在は「室内の環境音」の除去についての研究が進んでいます。
そして、音楽のデノイジングにおいて、以前から使われていたのが「Wiener Filter」という手法。これは金さんいわく「ほぼ教師あり学習だと思っている」というもので、きれいな音に対してノイズを加え、それにフィルターをかけてノイズ除去を目指します。勉強会ではより詳細なロジックについて解説がありました。
これに対して、今多く使われている「Denoising Autoencoder(DAE)」は、ノイズが入ったデータのみをインプット。インプットデータとクリーンなウェーブの情報を鏡移しの状態で比較しながら「どれがノイズか」を学習していく手法です。学習においては、CNN(Convolutional Neural Network)やLSTM(Long Term Short Memory)などを利用しますが、1つのノイズを学習させただけではそのノイズしか除去できないため、さまざまなノイズを学習させる必要があり、実際に、インプットするデータのノイズを調整しながら組んでいきます。
そして気になるのは、どこまでノイズが除去できるのか、というところ。ここはデモで実際の音を聞きました。ギターの演奏に、サーっというホワイトノイズが入った音が用意され、どこまでノイズが消えるのか試してみましょう。
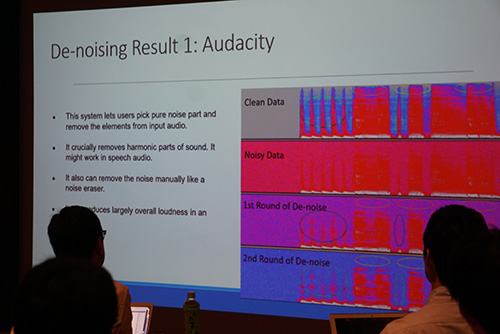
まずは「Audacity」というツール。これはユーザが「どこがノイズか」を指定し、指定された周波数のノイズをすべて消す仕組みをとっています。ただし!音楽の場合、楽器の響きをもたらす「倍音成分」も一緒に消されてしまうことに。デモを聞くと、デノイジング処理を1回かけると確かにノイズは少し減ったものの、その分ギターの音がひずんだ感じに。さらに2回目をかけると、ノイズは消えたものの、ギターも音の響きが消え、くぐもったような音になってしまいました。
そしていよいよInspiartプロジェクトで開発したDAEのデモを聞いていきます。先ほどと同様にホワイトノイズが入った音源を処理すると……ノイズが消え、ギターの高い音や響きもしっかり残っていました!このほか、iZOTOPEやAdobeの製品を使ったデモもありましたが、Inspiartプロジェクトで開発したノイズキャンセリングの精度の高さを感じられた発表でした。
デクリッピングに関する最新研究を解説
続いて「デクリッピング」、音割れの復元についての解説に移ります。音割れはマイクの性能が貧弱な場合や、データタイプの容量を超えたときなど、入力信号の限界を超えると発生します。
基本的にスピーカーやマイクは24bit Integer(整数型)でデータを扱っていますが、DAWやプラグインなどでは32bitか64bitのFloat(浮動小数点数型)で扱います。32bit/62bit Floatのデータをそのまま24bit Integerに変換すると、そのままでは音が割れたり聞こえなくなったりしてしまうため、32bit/62bit Floatで処理している間に音源を調整し、24bit Integerに変換しても音が割れないように制限する必要がある……ということです。
そして、パートごとに録音した音を重ね合わせて楽曲を生成する際も、データが大きくなりすぎてクリッピングを起こすことがあります。これを防ぐために、各音源のレベルをあわせてミキシングしなければならないのですが、音源をすべて同じレベルに調整すればよいわけではなく、ボーカルや特定の楽器を強調したりと、バランスが難しいところです。
パートごとに演奏したデータを機械学習でミキシングし、楽曲に仕上げることを目指しているInspiartプロジェクトでも、ここはまさに研究を進めている最中。どのようなアプローチで開発しようとしているのか、といった話に加えて、金さんが今最も注目している「A-SPADE」という企業と大学が共同研究したモデルについて、論文の内容の解説がありました。

デモでは、Adobeが開発した「Adobe Audition」と「A-SPADE」の2種類を聞き比べたのですが、Adobe Auditionが正直あまり変わっていない印象だったのに対し、A-SPADEではかなりキレイに音割れが復元されていました。音割れがここまできれいに復元できるというのは、なかなかの衝撃です。
Inspiartプロジェクトでは機械学習エンジニアを募集中!

勉強会終了後は、恒例の懇親会です。懇親会がはじまると早速金さんに勉強会の内容について質問している方が!3回の勉強会すべてにご参加いただいた方もおり、皆さんの注目度を感じます。勉強会の内容に関する議論のほか、どこの大学の論文をチェックしているか、といった情報交換もあり、有意義な時間となりました!

今回は、金さんがリーダーをつとめるInspiartチームが開発したノイズキャンセリングのデモの紹介もありましたが、Inspiartプロジェクトではノイズキャンセリングに続き、機械学習によるミキシングなどの開発を進めています。目指すは、音楽と機械学習の組み合わせによるこれまでにないサービス。このチームでは、ともに新しい挑戦に取り組む機械学習エンジニアを募集しています。目標やゴール、進捗は共有しながらも細かなプロセスや方法はそれぞれに任せるスタイル。自分自身で責任を持って開発を進められるので、やりがいも大きくなります。プロジェクトに興味をお持ちいただいた方、ぜひ下記バナーよりご応募ください。お待ちしております。

全3回の勉強会はこれで終了ですが、これからもInspiartプロジェクトの開発は進んでいきます。今後も、こういった機会を設けることで、多くの方とつながることができたら、と考えています。今回、参加いただいたみなさま、本当にありがとうございました!今後もEYSのInspiartプロジェクトにぜひご期待ください。
2nd Community 広報
2nd Community株式会社の広報です。EYS音楽教室や当社が運営する各教室のの最新ニュースやプレスリリースを更新します。
Share
