
















<第2回「音×機械学習」勉強会>レポート
音楽における機械学習の最新技術・トレンドを解説しました!
4月に第1回を開催した、「音×機械学習」エンジニア向け勉強会。ゴールデンウィークを挟んだので、1ヶ月があっという間に感じますが、5月16日に第2回を開催しました。今回は、高円寺にあるヴァル研究所さまのセミナールームをお借りしての開催。日中から気温が上がり、夏の気配すら感じた1日の終わりに、前回よりも大勢の方に参加いただきました!

今回も、勉強会講師はEYSのInspiartプロジェクトで音楽×機械学習の開発を手がける金さん。Inspiartプロジェクトでは機械学習による音楽のノイズキャンセリングやミキシングの実現を目指し、開発を進めています。これまで音楽の収録というと専用のスタジオでノイズが入らないように録音していましたが、いまやスマートフォンなどで誰でも気軽に演奏を録音できるようになりました。このスマホで録音した演奏から、ノイズを除去できたら嬉しいですよね。そして、楽曲のパートごとに演奏したデータのミキシングを機械学習で自動化できたら、音楽の可能性がグッと広がります。こういった音楽に関する機械学習はまだあまり研究が進んでいない分野であり、金さんをはじめとするエンジニアが日々試行錯誤しながら研究開発を進めています。
前回は、コールセンターや異常音検知など比較的ビジネス・産業寄りの領域で使われているアルゴリズムを紹介しましたが、今回はいよいよこの専門分野である「音楽に関する機械学習」をテーマに最新技術などを詳しく解説します!
音楽の機械学習において研究が進んでいる分野とは?
今回の勉強会でも最初に一般的な機械学習についてのおさらいからスタート。画像認識についてDNNでどうトレーニングするのか、どういった特徴量を利用するのかといった内容から、前回でも紹介のあった音声認識で一般的に利用されている特徴量であるMFCCについて細かな解説がありました。
そして本日のテーマの中心である「Music Information Retrieval」です。これは、「楽曲を、アルゴリズムを用いて操作したいときにどういった情報が必要なのかを探る」と定義されるもので、たとえば今、積極的に研究されているのは楽曲のリコメンドシステム。Spotifyをはじめとする楽曲配信システム・アプリの運営企業などがかなり積極的に投資しているのだとか。そのほかバンドやオーケストラなどで一斉に演奏したものを録音したデータからパートごとの音を抜き出す「音源分離」や、音楽信号から楽譜を書き起こす「Music Transcription」、楽曲のジャンル分けをおこなう「カテゴライゼーション」、さらには「楽曲の自動生成(Generation)」などさまざまな研究が進んでいます。

そしてこういった機械学習でもOSSが多く利用されています。機械学習関連のOSSのなかでも、音楽の分野でもっともよく使われており、金さん自身もよく使っているものとして「Librosa」を取り上げました。ほかにも最近は音楽の領域において「Madmom」というライブラリが登場し、こちらにも注目しているそうです。
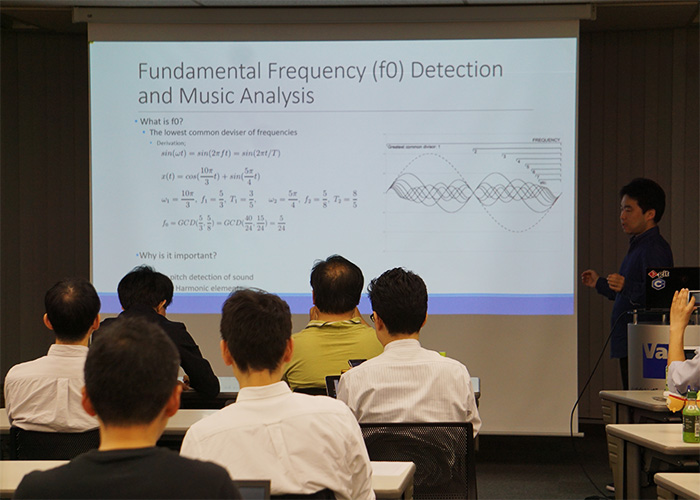
音楽の機械学習における「基本周波数」について
では、実際に音楽について機械学習で解析をおこなうにはどうするのでしょうか?その際に重要な要素である「基本周波数(Fundamental Frequency)」についてまず解説がありました。基本周波数は「1つの振動に対して1つの波が存在する状態」を指しますが、音楽の場合、たとえば1つの弦をはじくと、複数の波があらわれ、複数のサイン波の合成で表されます。このなかでもっともよく聞こえるものを基本周波数とし、これを基準とした「倍音」の波を探すことでハーモニーを見つけ出すのだとか。勉強会では、これらを導く数式も紹介し、詳しく解説。さらに実際にピアノ、ギター、チェロ、サックスなどさまざまな楽器で同じ音を演奏し、異なる波形が現れる様子を動画で紹介。同じ音を弾いていても、楽器ごとに倍音成分が異なるから、聞こえ方も違うということが目で見て分かり、興味深いデモでした。
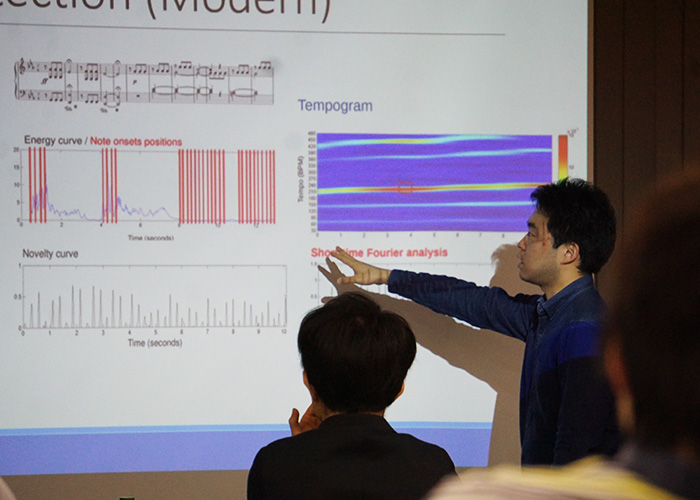
楽曲のテンポを分析するには?
さらに、音楽を分析するにあたって必要なのがテンポの分析です。たとえばコード進行を解析するとしても、一定の時間を区切って分析する必要がありますが、「一定の時間とはどれくらいの時間なのか」が問題になります。通常、こういったときは1テンポ(または1小節)で区切るため、まずは1テンポがどのくらいの時間なのかを導くビートディテクション/テンポディテクションが必要になる、ということです。
今回はその際に利用される「Key Extrapolation」という手法などが紹介されました。これは24のアプトプットがテンプレートとして含まれる辞書が用意されており、インプットした楽曲が辞書にどれだけ近いかを見る方法だそう。それとは別にコード進行を確率分布としてあらわした情報を付加することもでき、現在の精度は8割ほど。そして、金さんが個人的にもっとも注目しているのが「Tempogram」。それぞれの音が鳴りはじめた瞬間を取得し、正規化したうえでフーリエ変換することで、どういうテンポが積極的に出ているかが出力されるのだそう。楽曲のテンポは演奏が進むにつれてズレが出る場合もありますが、そういったケースも自動で調整し、曲全体のテンポを導き出せるのだとか。さらに途中でテンポが変わっても検出できるほか、3連符やシンコペーションなど音楽的にイレギュラーなものについても、一応検出できる……とかなり優秀。今後に期待が膨らみます。
楽曲を自動生成するAIの可能性
最後に紹介があったのが、楽曲の自動生成(Music Generation)です。Google社が「Google Magenta」という自動作曲のAIを発表したりと、今大きなトレンドになっている分野。Google Magentaはバリエーショナルオートエンコーダ(VAE)を利用しているのですが、会場で金さんがVAEを知っているか聞いたところ、半数以上の手が挙がりました。Magentaで使われているストラクチャについて解説があったあと、デモ動画を紹介。曲のはじめの音Aと終わりの音Bを用意すると、AとBの間が補完された曲が流れます。生成された部分が、思っていたよりも長く、またAとBは違った雰囲気の音だったにもかかわらず、曲の終わり部分が最初に聞いたBの音だったかどうか、パッと聞いて分かりません。つまりそれだけ自然にBの音につなげたと言えるでしょう。金さんいわく、これも環境変数などを調整することで、生成される曲が変わるのではないか、とのこと。

もちろんMagentaなどの楽曲自動生成は、人が作曲をおこなうことのサポートとしても期待されますが、それだけではありません。音楽の機械学習を進めるにあたっては、大量の教師データが必要になります。このデータの確保は課題のひとつですが、ここに楽曲自動生成の技術を活用できるのでは、と金さんは考えています。現状では1つの楽曲データのトーンを変えることでデータを増やしているそうですが、自動生成技術を活用することで違ったジャンルの曲に展開したり、1つのセンテンスから複数の曲を作成することも可能に。こういった技術がどこでどう花開いていくのか、今後が楽しみでなりません。
機械学習談義で盛り上がった懇親会!

勉強会終了後もそのまま会場をお借りして、懇親会をおこないました。前回から2回目の参加という方もいらっしゃり、今回も機械学習の話題でどのテーブルも盛り上がっていました。「この勉強会は抽選の倍率が高く、当日ギリギリに繰り上げ当選。参加できてよかった」など今回も嬉しい声をたくさんいただきました。普段から機械学習関連の仕事をされている方、趣味で勉強している方など幅広く参加いただき、「聞いたことがある技術でもこういう形で使うのか、という内容で新鮮だった」など、勉強会の内容も大変好評をいただいていました。
金さんがリーダーをつとめるEYSのInspiartプロジェクトでは、機械学習エンジニアを募集しています。冒頭でも紹介したとおり、Inspiartプロジェクトでは音楽の機械学習を手がけていますが、この分野はまだ論文も少なく、自分たちで試し、切り拓いていくしかありません。プロジェクトメンバーは「誰もやっていない、未知のエリアだからこそ面白い」とこの挑戦を楽しんでいる人ばかり。また金さんいわく「EYSでは、一人ひとりの働き方の要望にも柔軟に対応してもらえるので、働きやすいです」とのこと。プロジェクトに興味をお持ちいただいた方、ぜひ下記バナーよりご応募ください。お待ちしております。

第3回のテーマは「音楽におけるノイズ除去」。Inspiartプロジェクトで開発しているノイズ除去について、詳しく解説します。6/28(金)開催ですので、お申し込みをお待ちしております!
2nd Community 広報
2nd Community株式会社の広報です。EYS音楽教室や当社が運営する各教室のの最新ニュースやプレスリリースを更新します。
Share
